23.2 Graph Embedding as an Encoder / Decoder Problem
Many approaches to GRL follow a similar pattern:
- The network input (node features and graph edges ) is encoded from the discrete domain of the graph to embeddings
- The learned representation is used to optimize an objective (e.g., reconstructing the edges of the graph)
In this section, we will use the graph encoder-decoder model (GraphEDM) to analyze popular families of GRL methods, supervised and unsupervised. Some utilizes the graph as a regularizer, positional embeddings, or graph convolutions.
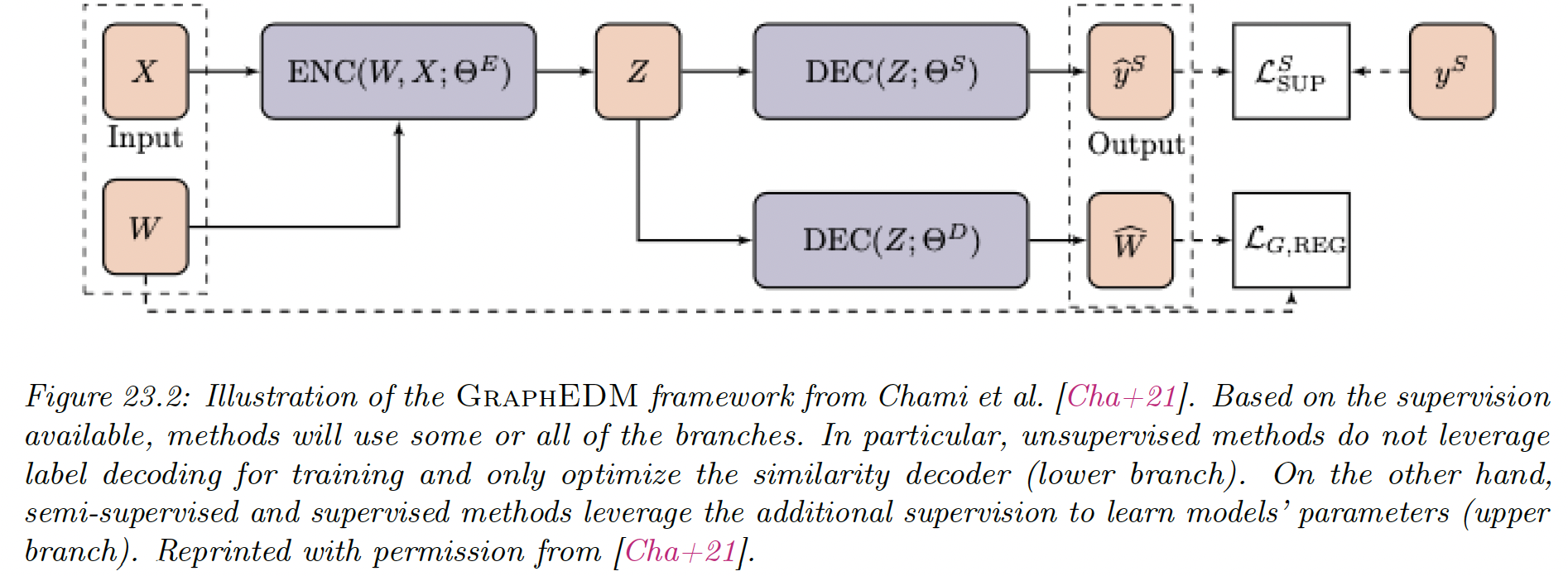
GraphEDM takes as input a weighted graph and optionally .
In (semi-)supervised settings, we assume that we have training target labels for nodes , edges or the entire graph . We denote the supervision signal .
We can decompose GraphEDM into multiple components:
GraphEncoder network
This might capture different graph properties depending on the supervision task.
GraphDecoder network
This compute similarity scores for all nodes pairs in matrix .
Classification network
where and is the label space.
This network is used in (semi-)supervised settings output a distribution over the labels.
Specific choices of the encoder and decoder networks allow GraphEDM to perform specific graph embedding methods, as we will explain.
The output of GraphEDM is either a reconstructed graph similarity matrix (often used to train unsupervised embedding algorithms) and/or labels for supervised applications.
The label output is task dependent, and can be node-level like , with representing the node label space.
Alternatively, for edge-level labeling, , with representing the edge-level label space.
Finally, we note other kinds of labeling are possible, like graph labeling , with representing the graph label space.
A loss must be specified to optimize . GraphEDM models can be optimized using a combination of three different terms:
where are hyper-parameters than can be tuned or set to zero, and:
- is a supervised loss term
- is a graph reconstruction loss term, leveraging the graph structure to impose regularization constraints on the model parameters
- is a weight regularization loss, allowing to represent priors on trainable model parameters to limit overfitting.