15.2 Recurrent neural networks (RNNs)
A RNN is a model mapping a sequence of inputs to a sequence of outputs in a stateful way.
The prediction depends on the input but also on the hidden state of the model that gets updated over time, as the sequence is processed.
We can use these models for sequence generation, sequence classification and sequence translation.
See this intro to RNNs by Karpathy (opens in a new tab).
15.2.1 Veq2Sec (sequence generation)
We now discuss how to learn functions of the form , were is the size of the input vector, and is an arbitrary-length sequence of vectors, each of size .
The output sequence is generated one token at the time. At each time step, we sample from the hidden state and then “feed it back in” in the model to get (which also depends on ).
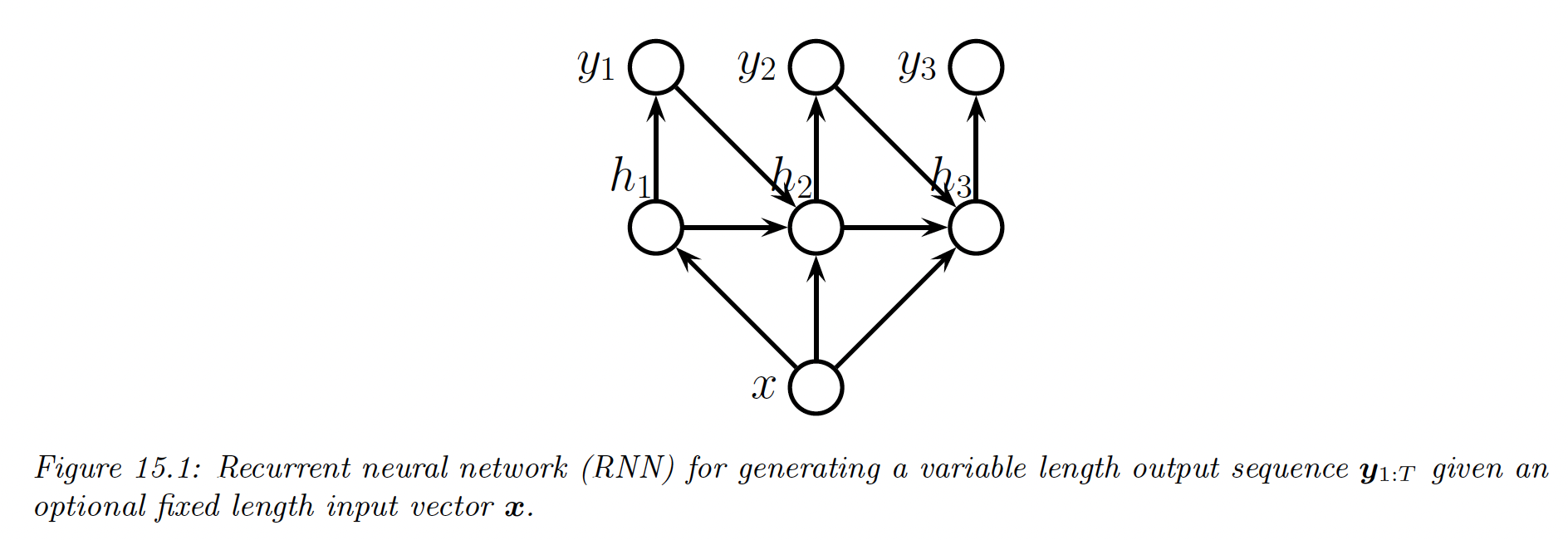
In this way, we define a conditional generative model of the form , which capture dependencies between output tokens.
15.2.1.1 Models
The RNN corresponds to the following conditional generative model:
where we define as the initial hidden state distribution, often deterministic.
Also, remember that is a random variable from which we sample .
The output distribution is given by:
For categorical values:
For numerical values:
The hidden state is computed deterministically:
where:
Therefore implictly depends on all past observations, as well the optional fix input .
Thus an RNN overcomes the limitation of a standard Markov models, in that they can be unbounded in memory. This makes the RNN theoretically as powerful as a Turing machine.
In practice, the length of the memory is determined by the size of the latent state and the strength of the parameters.
When we generate from a RNN, we sample from and feed it to compute deterministically. The stochasticity only comes from this sampling.
15.2.1.2 Applications
RNNs can be used to generate sequences unconditionally ( or conditionally on .
Unconditional sequence generation is also called language modeling and aims at learning the joint probability distribution over sequences of discrete tokens, i.e. models of the form
The result on the simple RNN below are not very plausible, but we can create better models with more data, measuring their performances using perplexity.

We can also make the generated sequence depends on some input vector . In the example below, is the embedding generated by a ConvNet on a image and the RNN is used to generate captions.
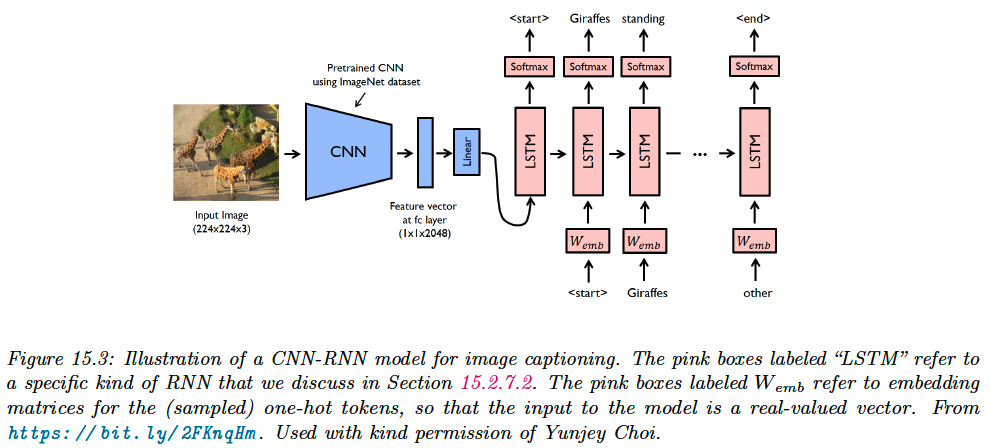
See this Pytorch implementation (opens in a new tab) of the model above.
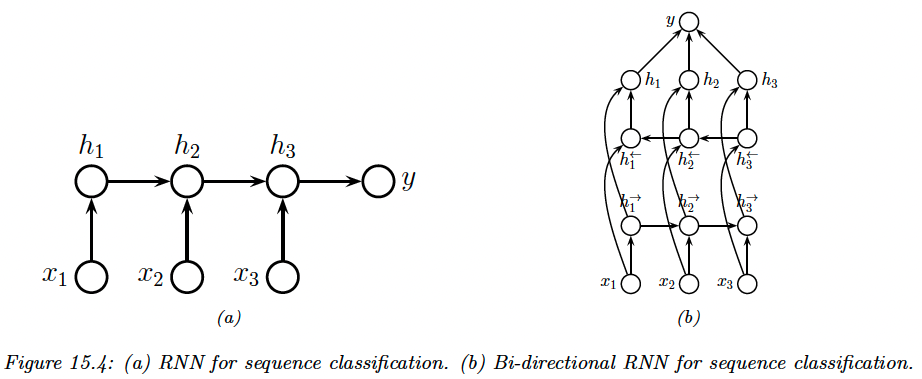
15.2.2 Seq2Vec (sequence classification)
We now predict fixed-length output with variable length sequences inputs. We learn a function of the form: .
The simplest approach is to use the final state of the RNN as input to the classifier:
We often can get better results if we let the hidden states depends on future and past context.
We do so by using two RNNs: one recursively computing hidden states in the forward direction, and another one in the backward direction.
This is called bi-directional RNN. We have:
Then we define to be the representation of the hidden states at time step , compounding past and future information.
Finally, we average pool over these hidden states to get the final classifier:
15.2.3 Seq2Seq (sequence translation)
In this section, we consider learning functions of the form .
We consider two cases:
- , the input and output sequences have the same length (aligned)
- (unaligned)
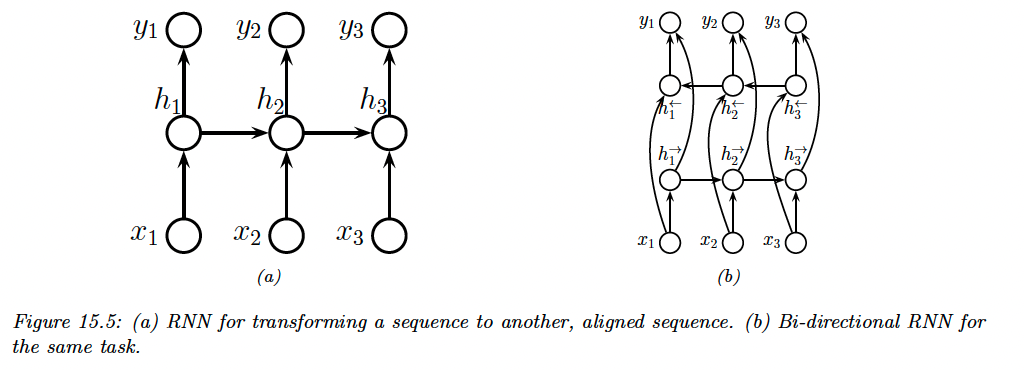
15.2.3.1 Aligned case
We can think of the aligned case as a dense sequence labeling where we predict one label per location.
This RNN corresponds to:
where is the initial state.
We can get better results by letting the decoder looks into the past and future of , by using a bi-directional RNN.
We can create more expressive models by stacking multiple hidden chains on top of each other.
This corresponds to:
The output is given by:
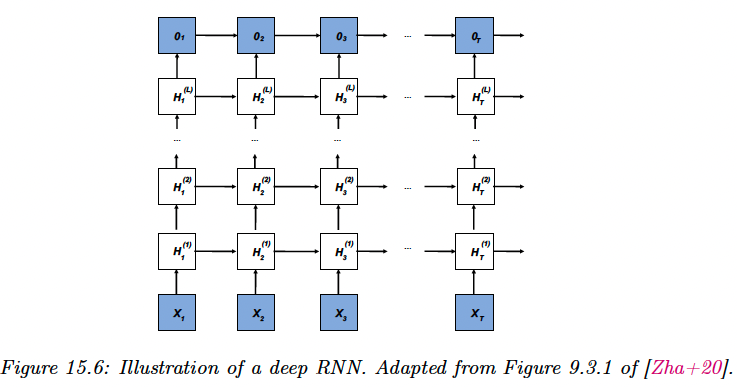
15.2.3.2 Unaligned case
We learn a mapping from one sequence of length to another of length .
We use an encoder to learn embeddings using the last hidden state (or average pooling over time steps for biRNN).
We then generate a sequence using a decoder
This is the encoder-decoder architecture.
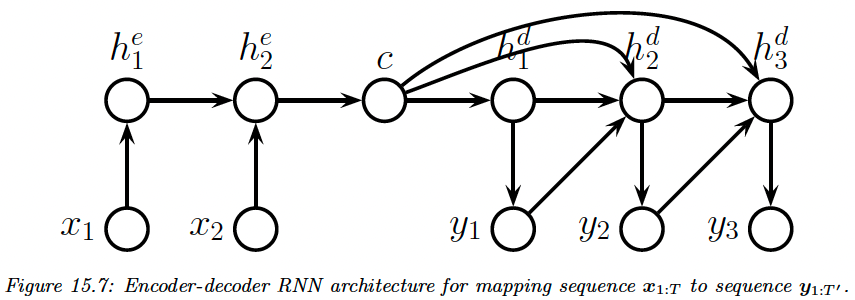
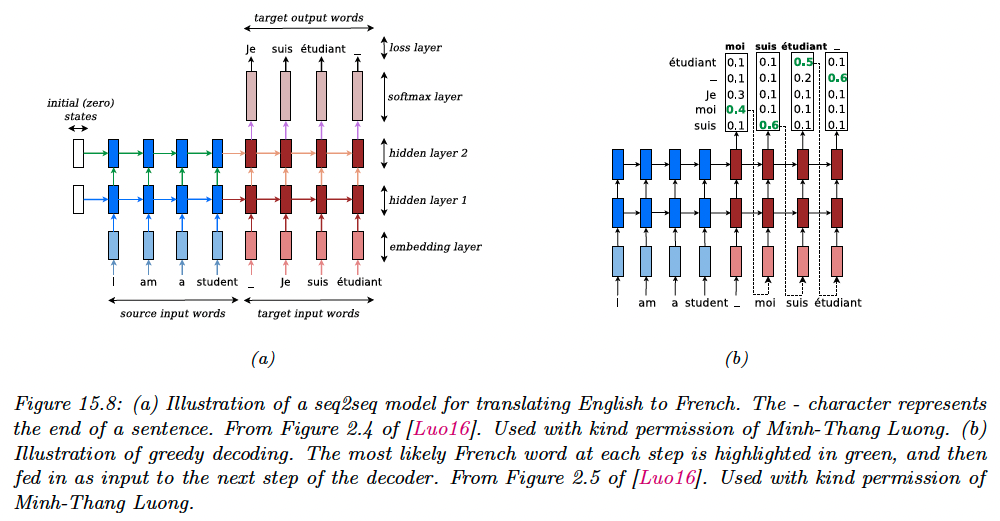
Neural machine translation is an important application (as opposed to the older approach called statistical machine translation).
15.2.4 Teacher forcing
When training a language model, the likelihood of a sequence of words is given by:
In an RNN, we set the output and the input .
Note that we condition on the ground truth from the past , not the labels generated by the model.
This is called teacher forcing since the teacher’s values are forced fed into the model at each time step (i.e. is set to ).
An issue of teacher forcing is that the model is only trained on correct inputs, so during testing it may not know what to do if it encounter an input sequence generated from the previous steps that deviate from what it saw during training.
The common solution is to use scheduled sampling (opens in a new tab). It starts with teacher forcing, then at some random time steps, feeds in samples from the model instead. The fraction this happens increases gradually.
An alternative solution is using models where MLE works better (1d CNN or Transformers).
15.2.5 Backpropagation through time
We compute the MLE of the RNN by solving:
To compute the MLE, we have to compute gradients of the loss w.r.t parameters. To do this, we unroll the computational graph, and then apply the backpropagation algorithm.
We compute the following model:
where are the output logits and we dropped the bias term for notational simplicity.
We assume are the true target labels at time step , and define the loss as:
We need to compute the derivative: . The latter term is easy, since it is local to each time step.
However, the first two terms depend on the hidden state, thus require to work backwards in time.
We simplify the notation by defining:
where is the flattened version of the weights and stacked together.
We focus on computing , by chain rule we have:
we expand the last terms as follow:
If we expand it recursively, we get the following:
However, this is takes to compute overall.
It is standard to truncate the sum to the most recent terms. It is possible to adaptively choose a suitable truncation parameter , but in practice it is set to the length of the subsequence in the current minibatch.
When using BPTT, we can train the model with batches of short sequences, created with non-overlapping windows from the original sequence.
If the subsequences are not ordered by time steps, we need to reset the hidden state for each batch.
15.2.6 Vanishing and exploding gradients
RNNs with enough hidden units can in principle remember inputs from long in the past.
Unfortunately, the gradient can vanish or explode through time, since we recursively multiply by at each time step forward, and by the Jacobian backward.
A simple heuristic is to use gradient clipping. More sophisticated methods attempt to control the spectral radius of the forward mapping as well as the backward mapping .
The simplest way to control the spectral radius is to randomly initialize so that and then keep it fixed. We only learnW_{hx}$$W_{ho}, resulting in a convex optimization problem.
This is called an echo state network (ESN). A similar approach called liquid state machine (LSM) uses binary-valued neurons (spikes) instead of continuous ones.
A more generic term for both ESNs and LSMs is reservoir computing. Another approach to this problem is to use constrained optimization to ensure stays orthogonal.
An alternative to explicitly controlling the spectral radius is to modify the architecture of the RNN itself, to use additive rather than multiplicative weights, similar to residual nets. This significantly improves training stability.
15.2.7 Gating and long term memory
We now focus on solutions were we update the hidden state in an additive way.
15.2.7.1 Gating recurrent units (GRU)
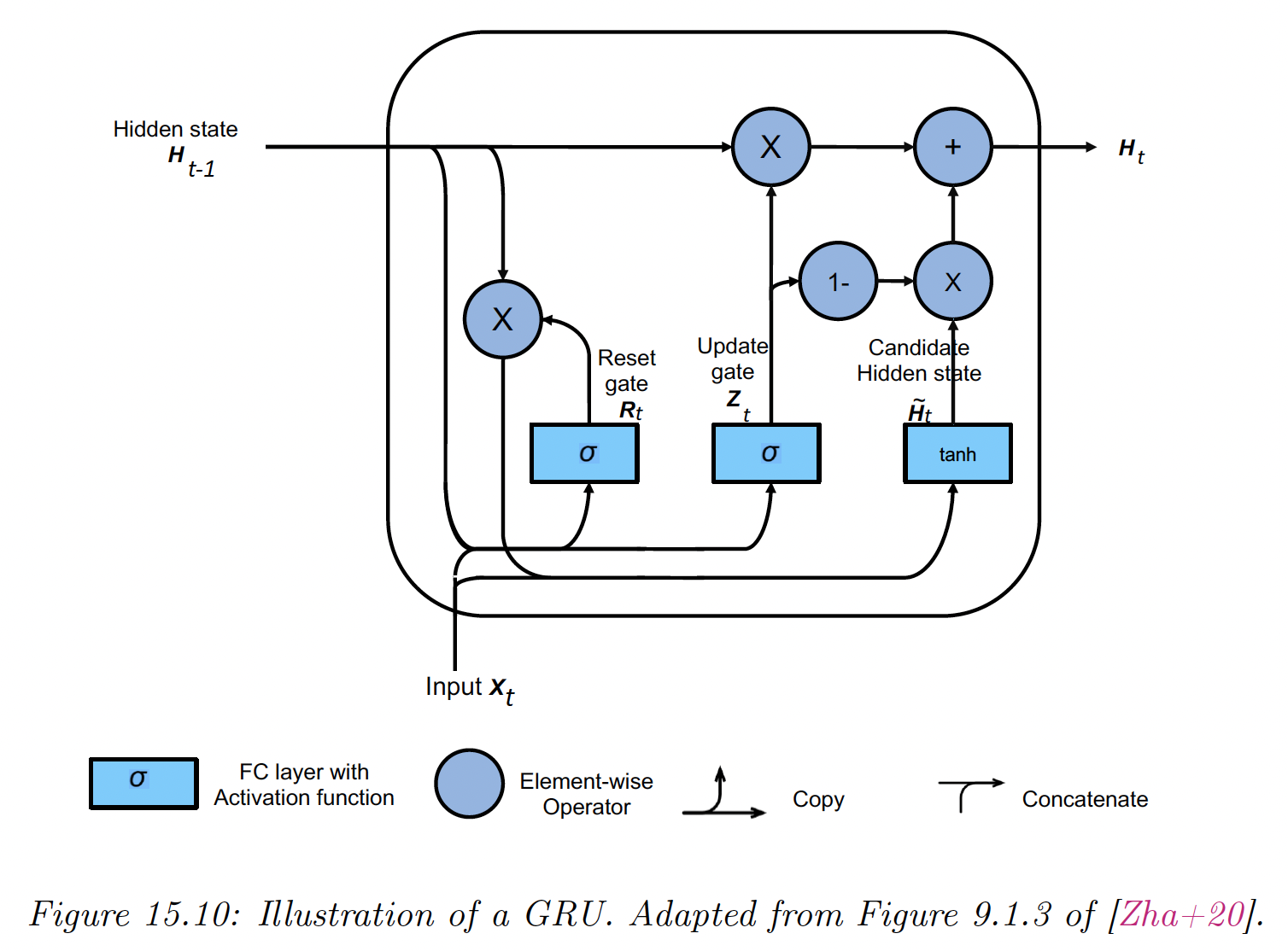
We assume , where is the batch size and is the vocabulary size. Similarly, where is the number of hidden units.
The reset gate and update gate are computed as:
Note that each elements of and is in because of the sigmoid.
We then define a candidate next vector using:
This combines the old memories that are not reset with the new inputs.
If the entries of the reset gate are close to 1, we get the regular RNN update.
If these entries are close to 0, we don’t use memories and the update is the regular MLP.
Once we have computed the new candidate state, we compute the actual new state:
When an update gate value is close to 1, we dismiss the new inputs and capture long term dependencies.
15.2.7.2 Long short term memory (LSTM)
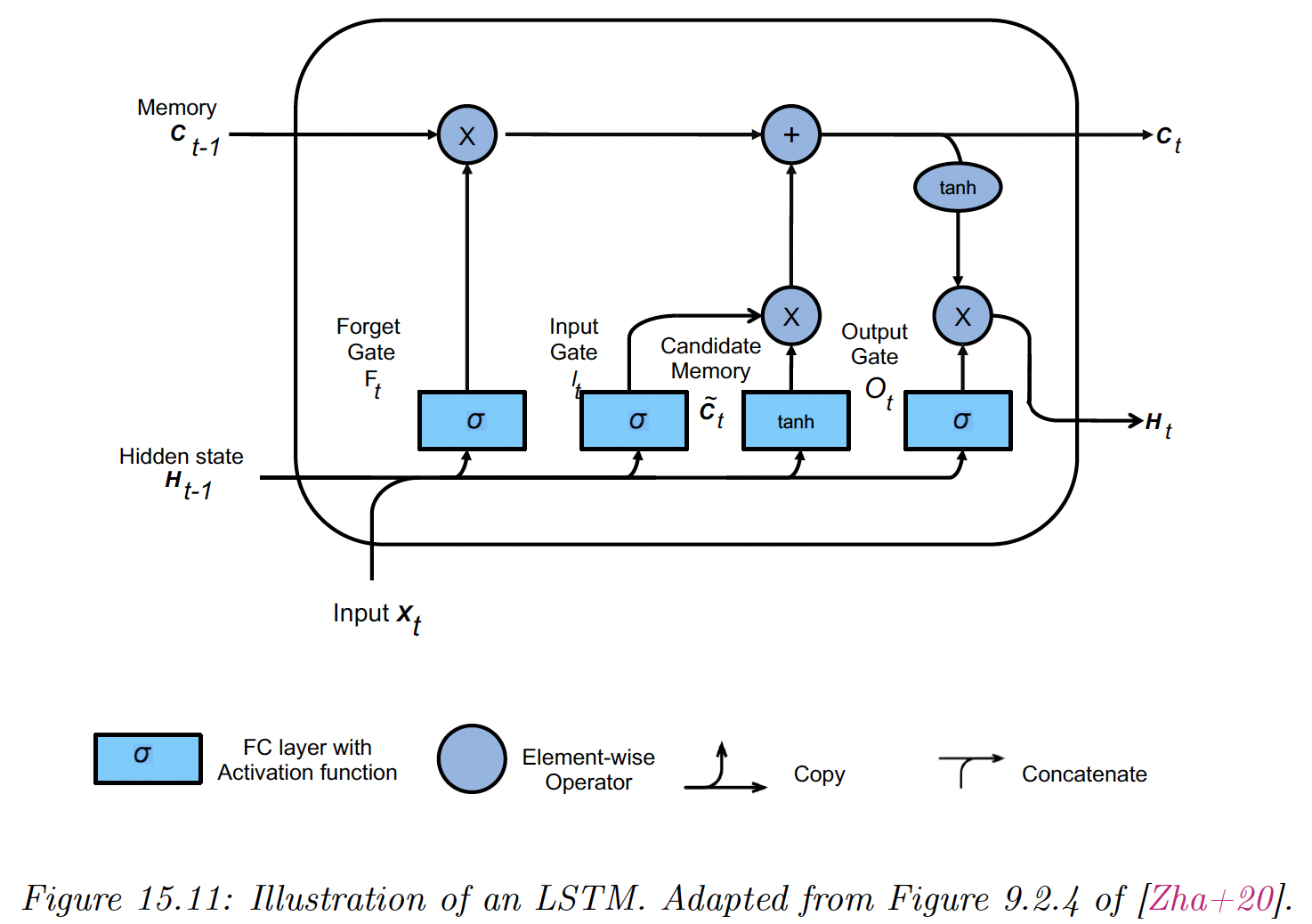
LSTM is a more sophisticated model than GRU, even if it pre-dates it by almost 20 years.
The main idea is to augment the state with a memory cell .
We need three gates to control this cell:
- the output determines what gets read out
- the input determines what gets read in
- the forget determines when we should reset the cell
We compute them as:
We then compute a new candidate cell:
The actual update to the cell is a combination between the old cell or the candidate cell:
When and , this can remember long terms dependencies.
Finally, we compute the hidden state as a transformed version of the cell, provided the output gate is on:
Note that plays both the role of the output of the cell and the hidden state of the next step. This lets the model remember what it has just output (short term), whereas deals with the long term memory.
Many variants of the LSTM have been introduced, but this architecture has good performances for most tasks.
15.2.8 Beam search
The simplest way to generate from a RNN is to use greedy decoding, where we compute at each step:
We can repeat this process until we generate the “end of sentence” token.
However, this will not generate the MAP sequence:
The reason is that locally optimum at step might not be on the globally optimum path (see figure below, where the likelihood is the product of all blue items).
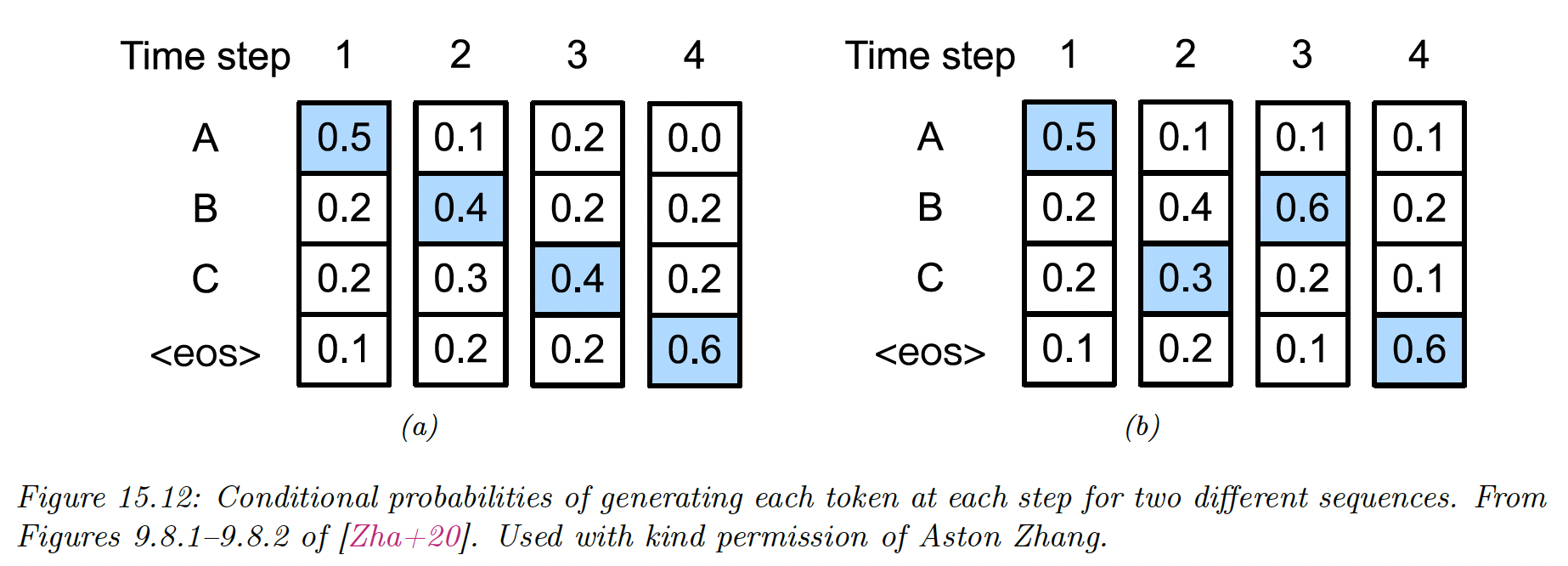
For hidden Markov models, we can use Viterbi decoding (which is an example of dynamic programming) in where is the vocabulary size.
But for RNN, computing the global optimum takes , since the hidden state is not a sufficient statistic for the data.
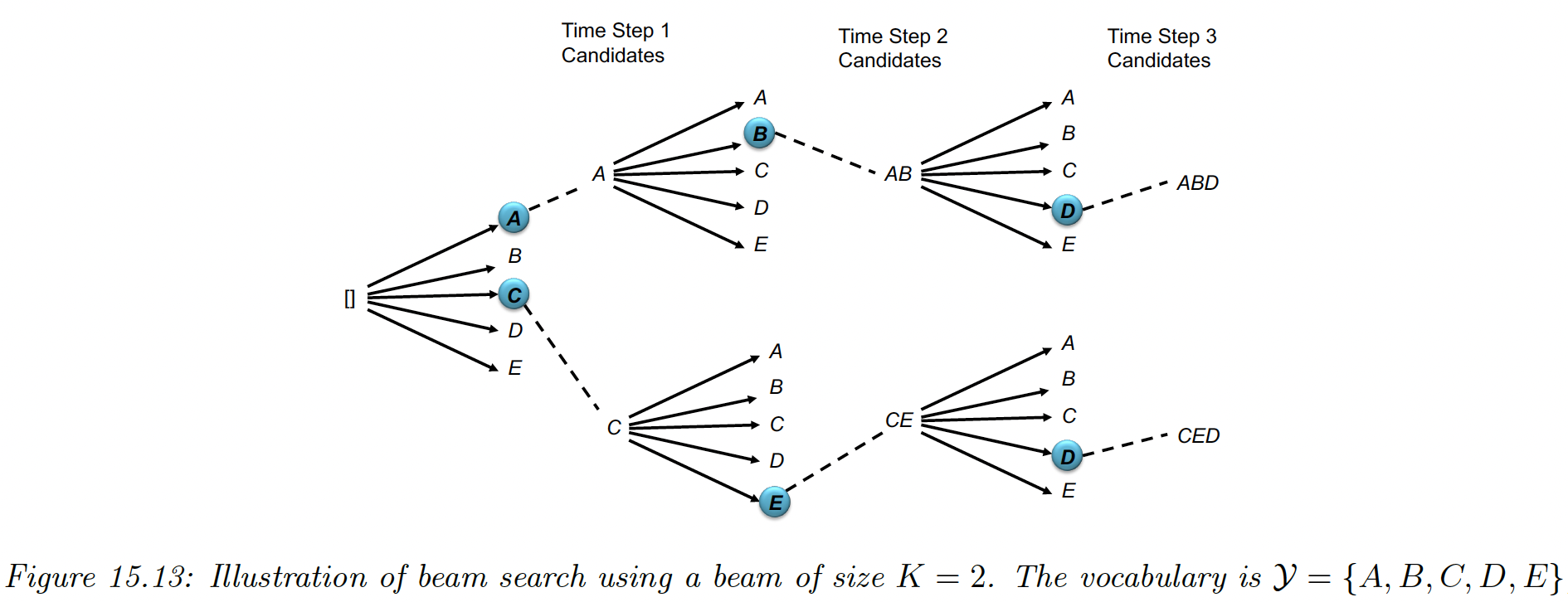
Beam search is a faster heuristic, where we only keep the best path at any time step. We then expand for every possible way, generating candidates. We only takes the best, and iterate.
This algorithm takes .
We can also sample the top outputs without replacement. This is called stochastic beam search, where we add Gumbel noise to perturb the model partial probability at each step.