19.5 Meta-learning
We can think of a learning algorithm as a function that maps data to a parameter estimate .
The function usually has its own parameter , such as the initial values for or the learning rate. We get .
We can imagine learning itself, given a collection of dataset and some meta-learning algorithm , i.e. .
We can then apply on a new dataset to learn the parameters . This is also called learning to learn.
19.5.1 Model agnostic Meta-learning (MAML)
A natural approach to meta-learning is to use a hierarchical Bayesian model.
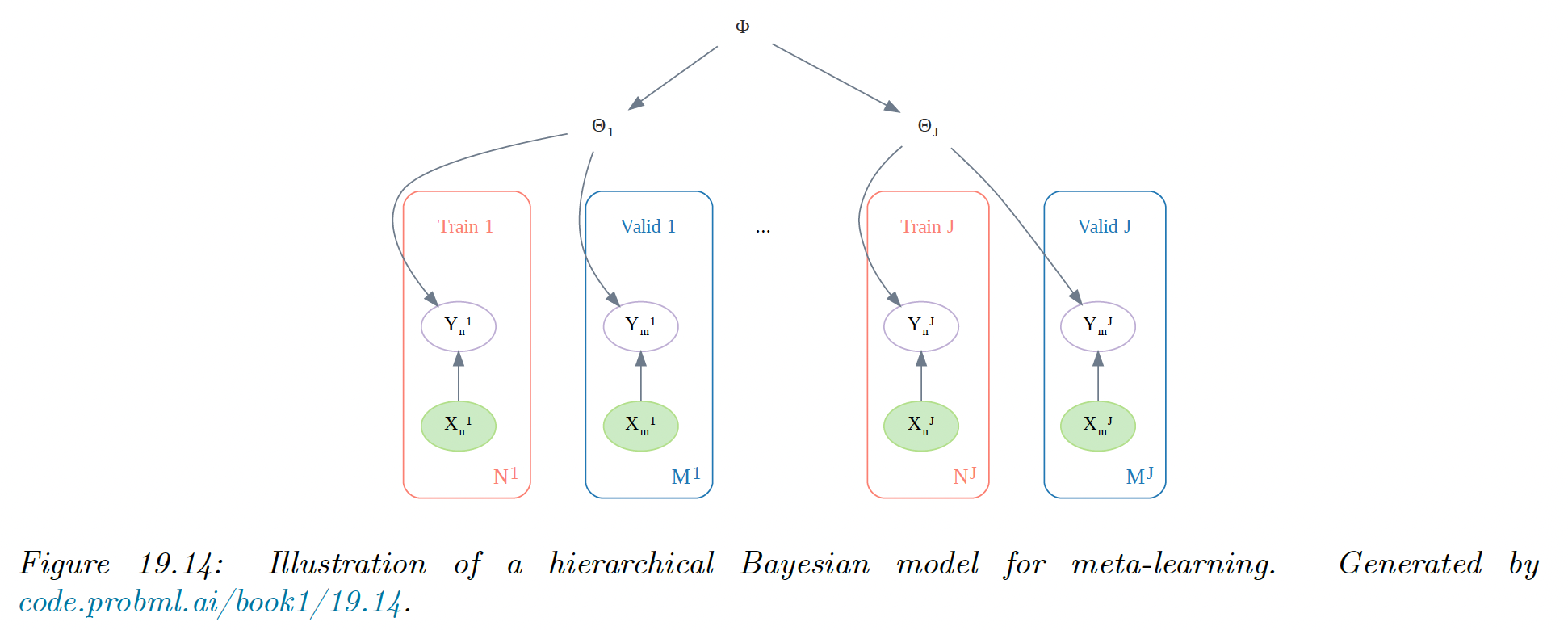
We can assume that the parameters come from a common prior , which can be used to help pool statistical strength from multiple data-poor problems.
Meta-learning becomes equivalent to learning the prior . Rather than performing full Bayesian inference, we use the following empirical Bayes approximation:
where is a point estimate of the parameters of task , and we use cross-validation approximation to the marginal likelihood.
To compute the point estimate of the parameters for the target task , we use steps of a gradient ascent procedure, starting from with a learning rate . This is known as model agnostic meta-learning (MAML).
This can be shown to be equivalent to an approximate MAP estimate using a Gaussian prior centered at , where the strength of the prior is controlled by the number of gradient steps (this is an example of fast adaptation of the task specific weights from the shared prior ).