15.4 Attention
So far, we have only considered hidden activations as , where is a fixed set of learnable weights.
However, we can imagine a more flexible model where we have a set of feature vectors , and the model dynamically decides which feature to use, based on the similarity between an input query and a set of keys .
If is most similar to , we use . This is the basic idea behind attention mechanisms.
Initially developed for sequence models, they are now used in a broader set of tasks.
15.4.1 Attention as a soft dictionary lookup
To make this lookup operation differentiable, instead of retrieving a single value , we compute a convex combination as follow:
where is the ith attention weight, and , , computed as:
with the attention score function .
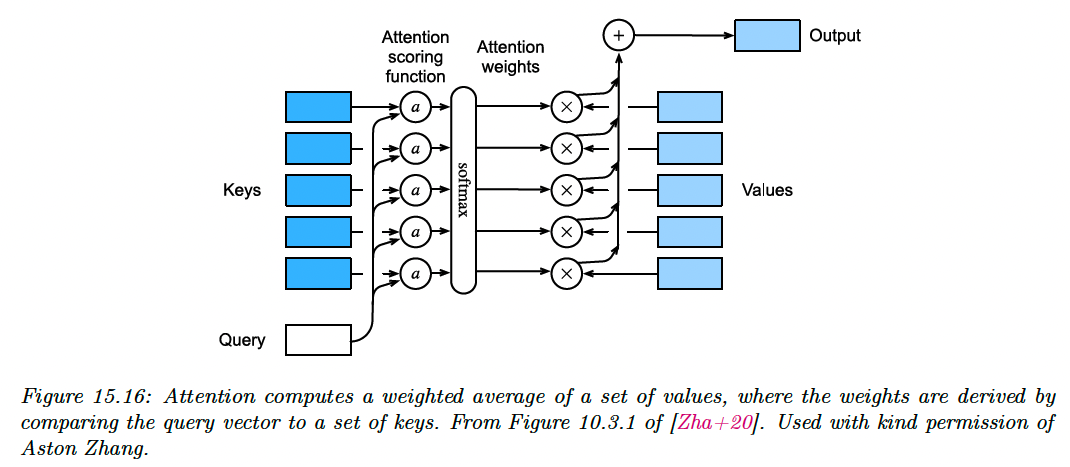
In some cases, we want to restrict attention to a a subset of the dictionary. For example, we might pad sequences to a fix length (for efficient mini-batching), and “mask out” the padded locations. This is called masked attention.
We implement this by setting the attention score to large negative number like , so that the exponential output will be zero (this is analogous to causal convolution).
15.4.2 Kernel regression as non-parametric attention
Kernel regression is a nonparametric model of the form:
The similarity is computed by using a density kernel in the attention score:
where is called the bandwidth. We then define .
Since the score are normalized, we can drop the term and write it:
Plugging this into the first equation gives us:
We can interpret this as a form of nonparametric attention, where the queries are the test points , the keys are the training points and the values are the training labels .
If we set , we obtain the attention matrix for test input :
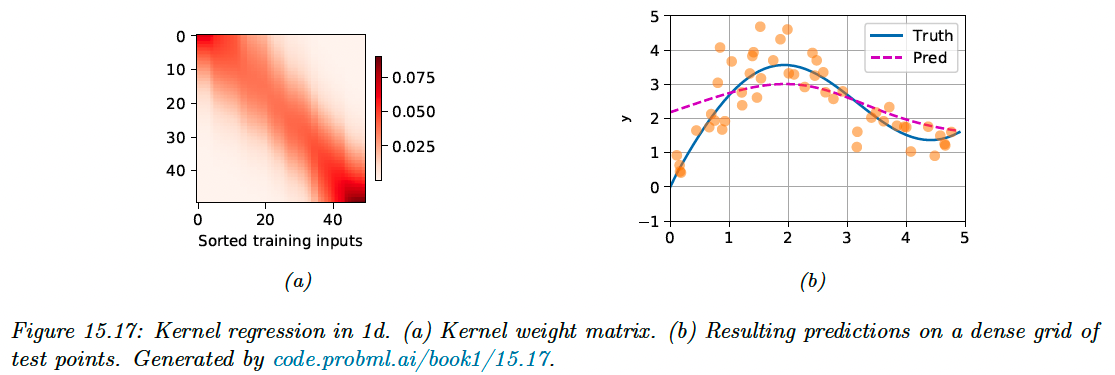
The size of the diagonal band of figure 15.17a narrows when augment, but the model will start to overfit.
15.4.3 Parametric attention
Comparing a scalar query (test point) to each of the scalar values in the training set doesn’t scale well to large training sets, or high-dimensional inputs.
In parametric models, we have a fixed set of keys and values, and we compare keys and queries in a learned embedding space.
One general way to do it is assuming and might not have the same size, so we compare them by mapping them in a common embedding space of size .
This gives us the following additional attention function:
with ,
A more computationally efficient approach is to assume the keys and queries both have the same size .
If we assume these to be independent random variables with mean 0 and unit variance, the mean of their inner product is 0 and their variance is , since .
To ensure the variance of the inner product stays 1 regardless of the size of the inputs, we divide it by .
We can define the scaled dot-product attention:
In practice, we deal with minibatch of vectors at a time. The attention weighted output is:
with and the softmax function applied row-wise.
15.4.4 Seq2Seq with attention
In the seq2seq model from section 15.2.3, we used a decoder in the form:
where represents the fixed-length encoding of the input . We usually set , the final state of the encoder (or average pooling for bidirectional RNN).
However, for tasks like machine translation, this can result in poor predictions, since the decoder doesn’t have access to the input words themselves.
We can avoid this bottleneck by allowing the output words to “look at” the input words. But which input should them look at, since each language has its own word order logic?
We can solve this problem in a differentiable way by using soft attention, as proposed by this paper (opens in a new tab). In particular, we can replace the fix context vector in the decoder with a dynamic context vector computed as:
where the query is the hidden state of the decoder at the previous step, and both the keys and values are all the hidden state of the encoder. When the RNN has multiple hidden layers, we take the one at the top).
We then obtain the next hidden state as:
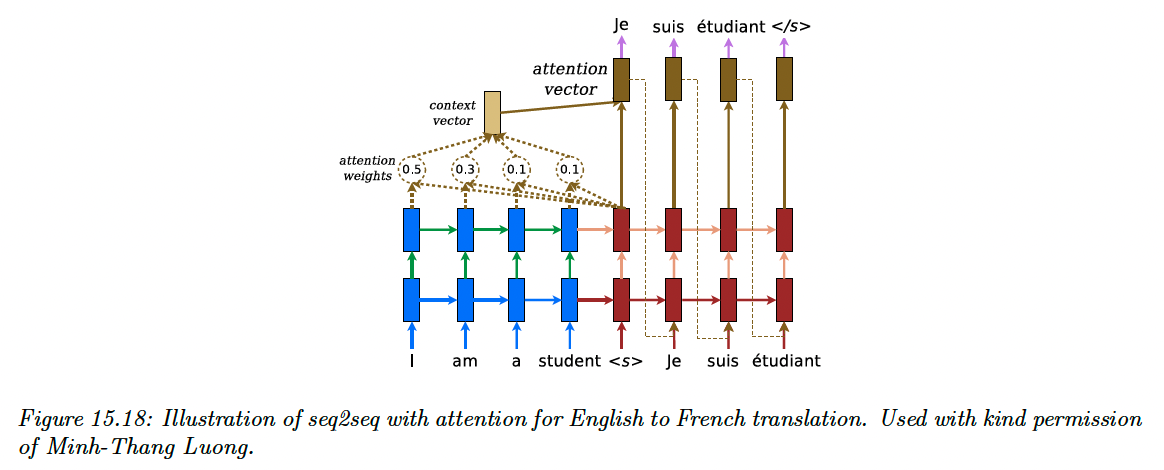
We can train this model the usual way on sentence pairs.
We can observe the attention weights computed at each step of decoding to determine which input words are used to generate the corresponding output.
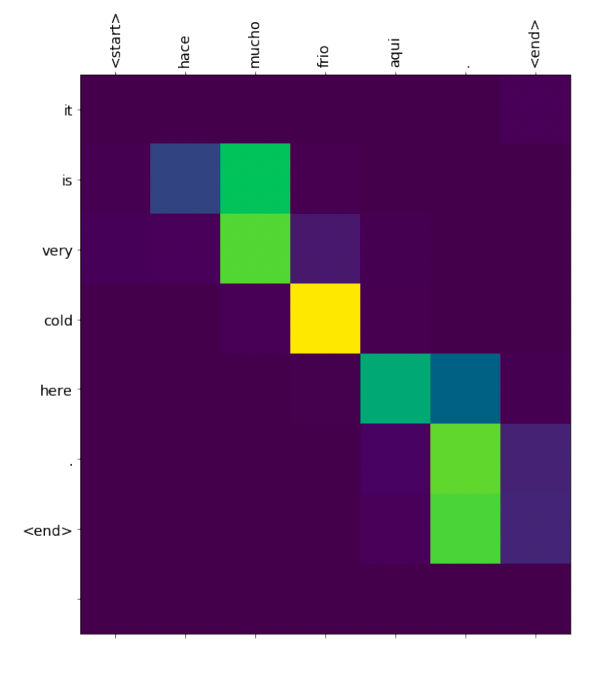
Each output word was sampled from (query, vertical axis), and each line represent the attention of this decoder hidden state with all the encoder hidden states (keys, horizontal axis).
15.4.5 Seq2Vec with attention (text classification)
We can also use attention with sequence classifiers. For example, this paper (opens in a new tab) applies an RNN classifier to predict the death of patients. It uses a set of electronic health record as input, which is a time series containing structured data as well as unstructured text (clinical note).
Attention is useful for identifying the “relevant” parts of the inputs.

15.4.6 Seq+Seq2Vec with attention (text pair classification)
Our task is now to predict whether two sentences (premises and hypothesis) are in agreement (premises entails the hypothesis), in contradiction or neutral.
This is called textual entailment or natural language inference. A standard benchmark is Stanford Natural Language Inference (SNLI) corpus, consisting in 550,000 labeled sentence pairs.
Below is a solution to this classification problem presented by this paper (opens in a new tab).
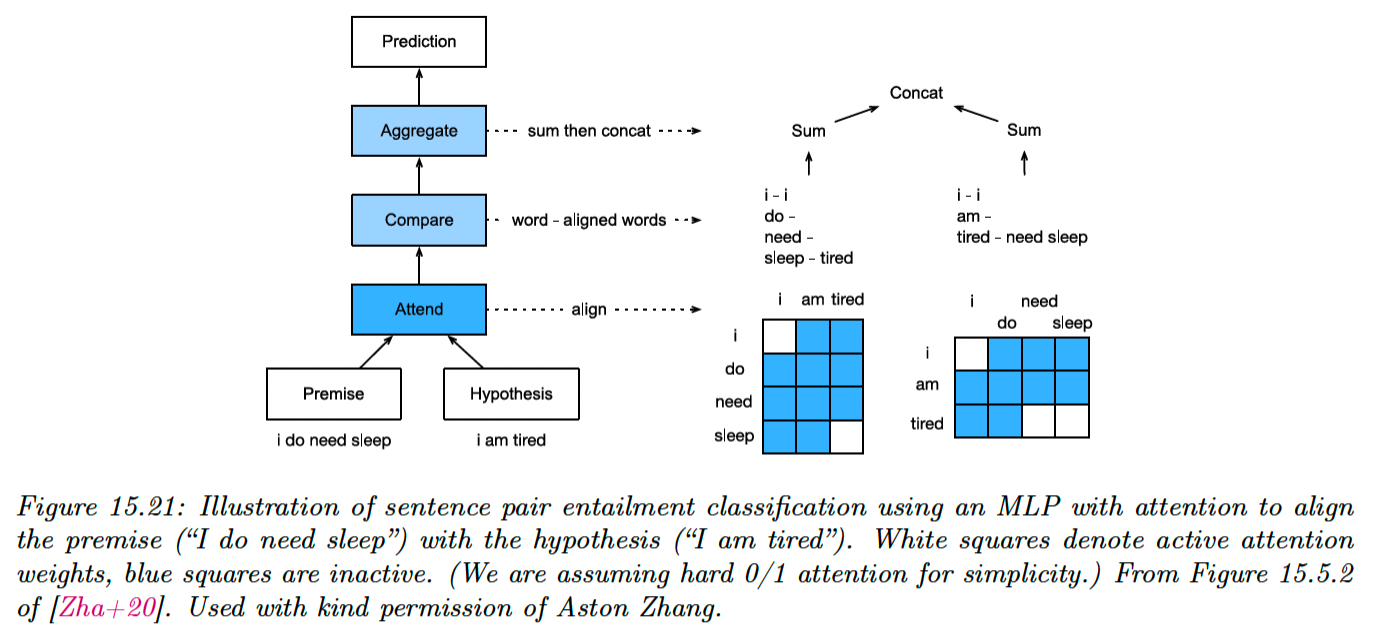
Let be the premise and by the hypothesis, with the words embedding vectors.
First, each word in the premise attends to each word in the hypothesis, to compute an attention weight:
where is an MLP.
We then compute a weighted average of the matching words in the hypothesis:
We compare and by mapping their concatenation to a hidden space using an MLP :
Finally, we aggregate over the comparison to get an overall similarity of premise to hypothesis:
We can similarly get an overall similarity of hypothesis to premises by computing:
At the end, we classify the output using another MLP :
We can modify this model to learn other kinds of mappings from sentence pairs to label. For instance, in the semantic textual similarity task, we predict how semantically related two inputs are.
15.4.7 Soft vs hard attention
If we force the attention heatmap to be sparse, so that each output only attends to a single input location instead of a weighted combination of all of them, we perform hard attention.
We compare these two approaches in image captioning:

Unfortunately, hard attention is a nondifferentiable training objective, and requires methods such as reinforcement learning to fit the model.
It seems that attention heatmaps can explain why a model generates a given output, but their interpretability is controversial.
See these papers for discussion:
Is attention interpretable? (opens in a new tab)
On identifiability of transformers (opens in a new tab)