8.7 Bound optimization
8.7.1 The general algorithm
Our goal is to maximize some function , such as the log-likelihood. We construct a tight lower-bound surrogate function such that:
If these conditions are met, we use the update:
This guarantees the monotonic increases of the original objective:
This iterative procedure will converge to a local minimum of the .
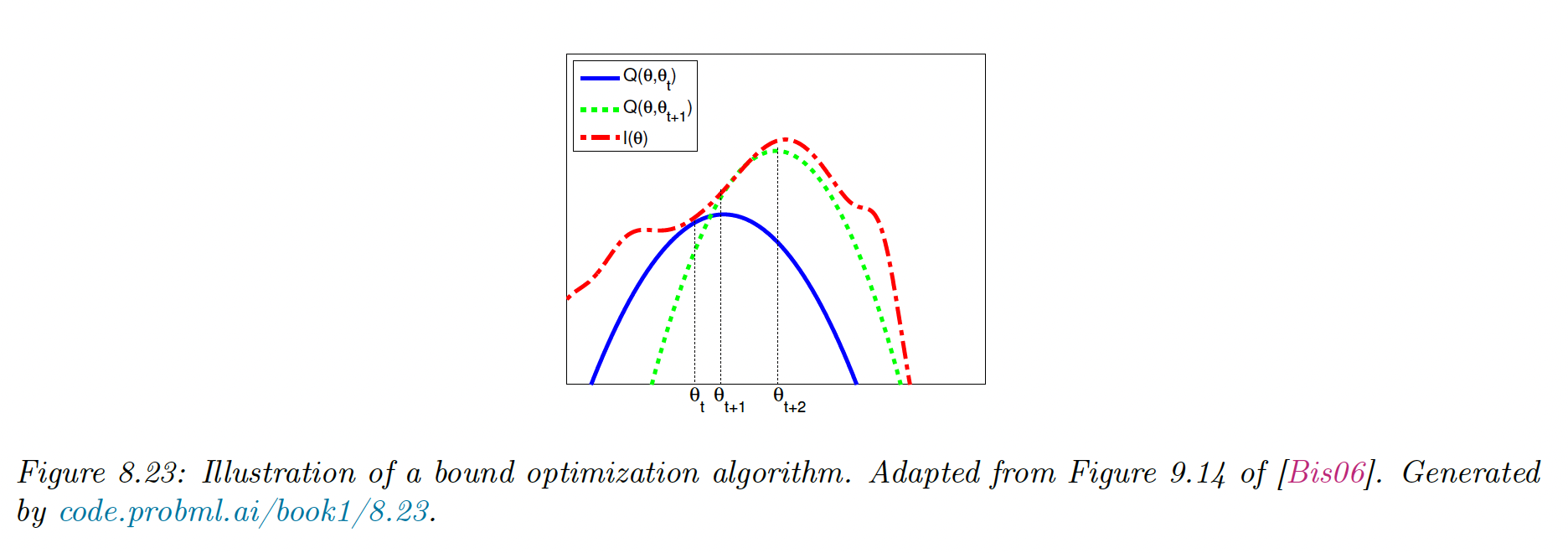
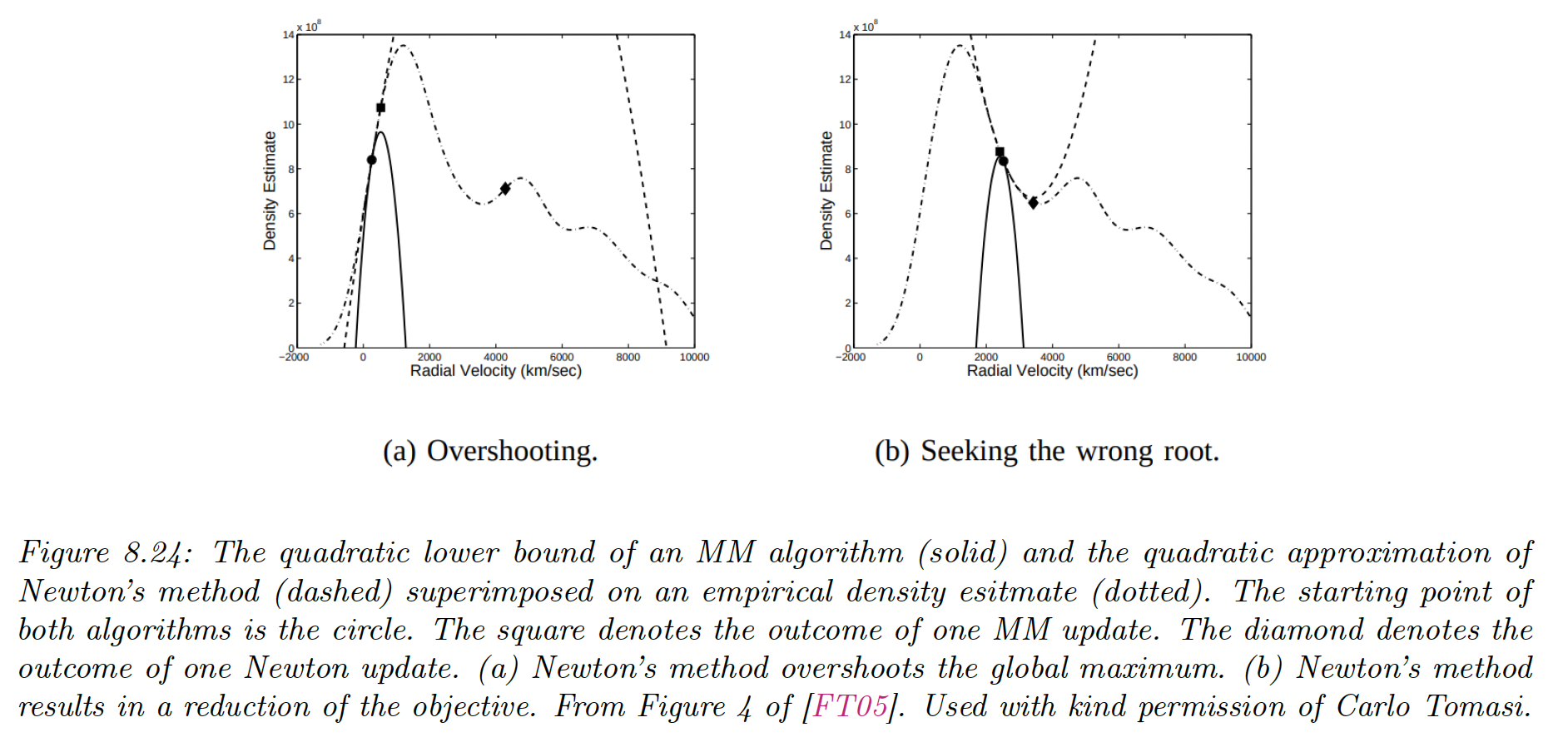
If is quadratic, then the bound optimization is similar to Newton’s method, which repeatedly fits and optimizes a quadratic approximation.
The difference is that optimizing is guaranteed to improve the objective, even if it is not convex, whereas Newton may overshoot or lead to a decrease in the objective since it is a quadratic approximation, not a bound.
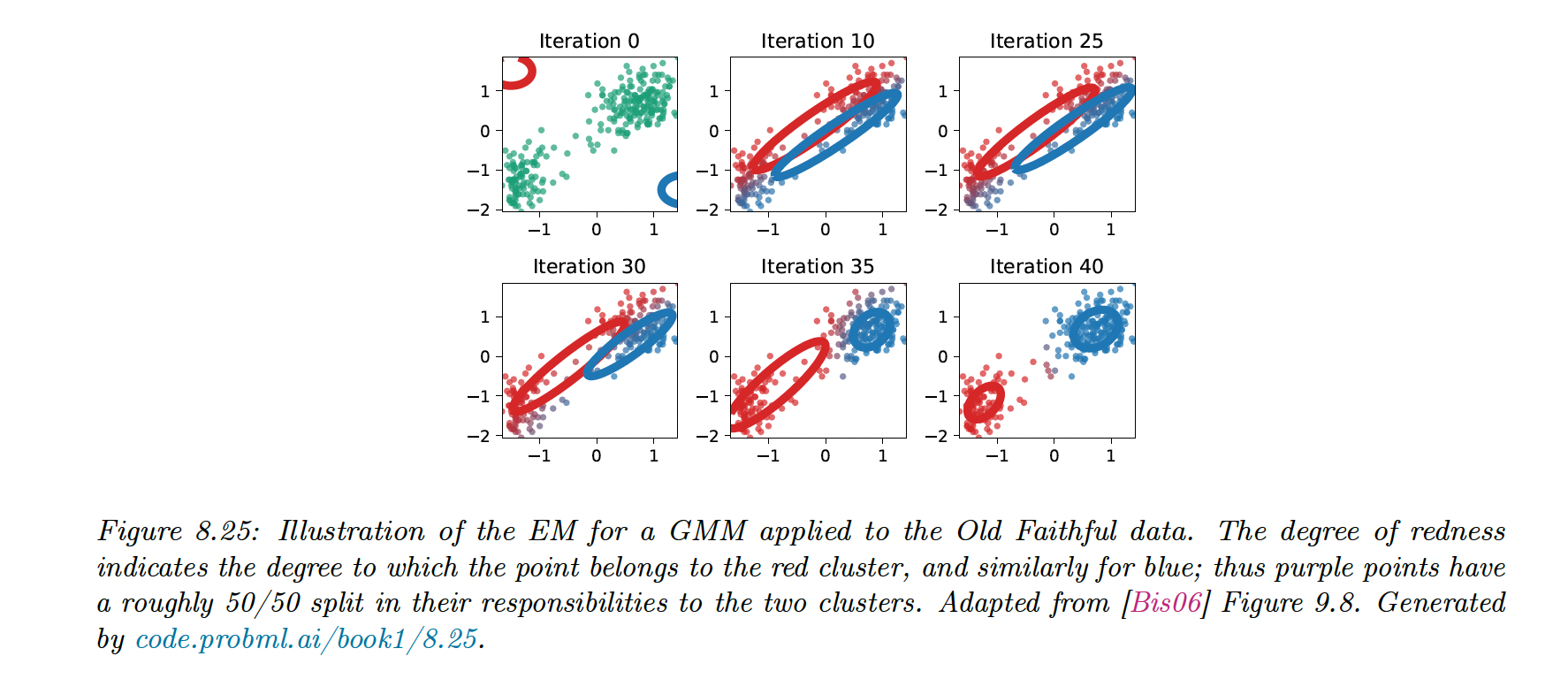
8.7.2 The EM Algorithm
8.7.2.1 Lower bound
The goal of the EM is to maximize the log-likelihood:
where are the visible and the invisible variables.
To push the into the sum, we consider arbitrary distributions :
Eq 2. used Jensen’s inequality since is a concave function and
is called Evidence Lower Bound (ELBO), optimizing it is the basis of variational inference.
8.7.2.2 E step
We estimate the hidden variables
We can maximize this lower bound by setting . This is called the E step.
We can define:
Then we have and as required.
8.7.2.3 M Step
We compute the MLE by maximizing w.r.t , where are the distributions computed during the E step at iteration .
Since is constant w.r.t , we can remove it. We are left with: